

Réf. ITSM_M0500-V010-001

Réf. ITSM_M0500-V010-002
Les équilibres à trouver #
La position particulière de l’exploitation dans le cycle de vie des services

L’exploitation des services est très souvent considérée uniquement dans son rôle de gestion quotidienne (opérations) et de gestion technique.
Mais elle s’intègre dans le cadre plus global du cycle de vie des services où elle est responsable :
de l’exécution et de l’aboutissement des processus qui optimisent le coût et la qualité des services
vis-à-vis de l’organisation, de permettre aux organisation d’affaires d’atteindre leurs objectifs
vis-à-vis de la technologie, du bon fonctionnement des composants techniques qui, assemblées, constituent les services

L’exploitation des services consiste à trouver une position d’équilibre entre tous ces rôles et à gérer les aspects quotidiens tout en conservant à l’esprit la perspective plus globale du cycle de vie des services.
Trouver un équilibre
L’exploitation des services est plus que l’exécution répétitive d’un ensemble de procédures et d’activités standardisées.
Les fonctions et les processus sont conçus pour fournir des niveaux de services validés et constants … mais ils doivent être délivrés dans un environnement en perpétuelle évolution.
Cela crée un conflit entre maintenir un status quo et s’adapter aux changements techniques et d’affaires.
Un des rôles-clés de l’exploitation des services est de gérer ce conflit et de trouver un équilibre entre des priorités contradictoires.
Chaque situation conflictuelle représente une opportunité de s’améliorer.
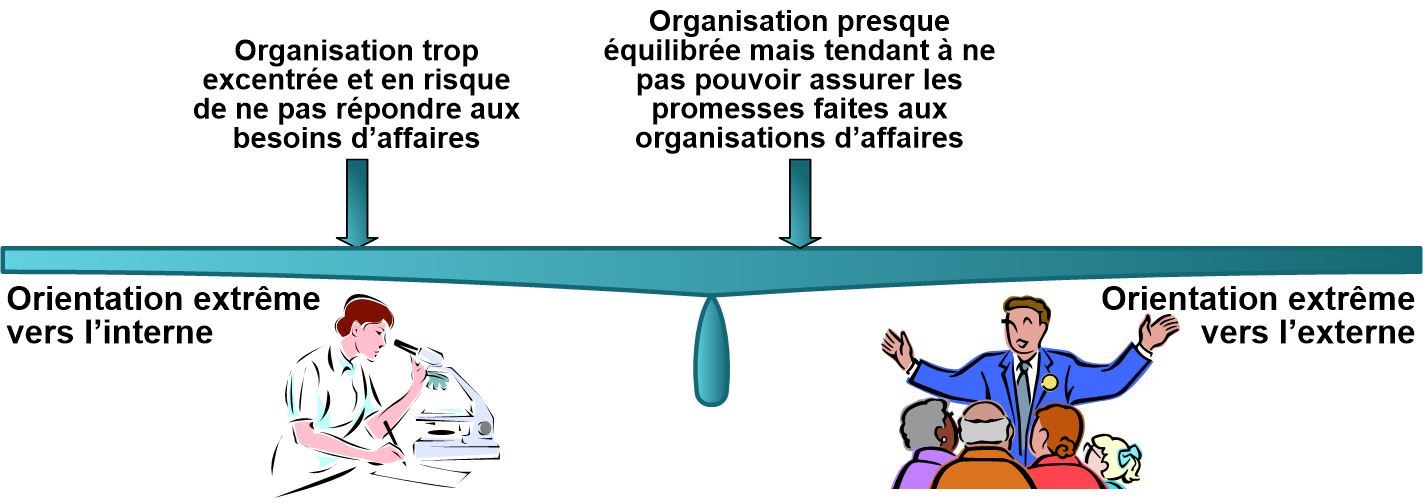
Conflit numéro 1 : la vue interne des TI face à la vue externe affaires
la vue externe affaires (« l’organisation des TI fournit des services ») : les utilisateurs et clients ne comprennent pas toujours (voire ne se sentent pas concernés) par le détail des composants techniques utilisés pour fournir ces services, leur seule préoccupation est que les services soient délivrés conformément à leurs besoins et ce qui a été convenu avec les TI
la vue interne TI (« l’organisation des TI gère des composants techniques ») : la complexité croissante des technologies entraînent souvent que les équipes techniques sont organisées en silos et se concentrent sur des performances et disponibilité optimales de « leurs » systèmes
Les deux points de vue sont nécessaires pour fournir correctement les services :
trop orientée services sans se préoccuper de la manière dont les composants techniques interviennent dans la fourniture, l’organisation des TI risque de faire des promesses qu’elle ne pourra pas tenir
trop orientée technique sans se préoccuper de la manière dont les services sont construits à partir des composants techniques, elle risque de fournir des services coûteux sans grande valeur ajoutée
Le risque potentiel de conflit entre ces deux positions dépend de beaucoup de paramètres comme la maturité de l’organisation, sa culture, son histoire, etc.
Toutes les organisations se positionnent entre des deux extrêmes.
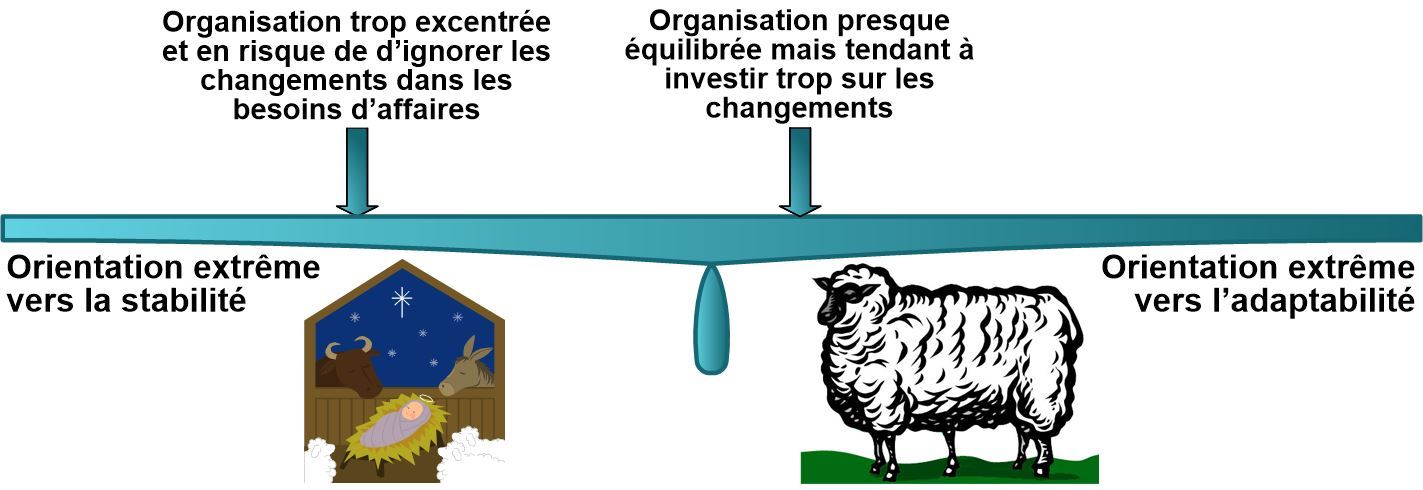
Conflit n°2 : stabilité contre adaptabilité
Si un service répond fonctionnellement à un besoin et s’il a été bien conçu, cela ne sera pas satisfaisant si les composants du service ne sont pas disponibles ou fonctionnent mal.
L’exploitation doit assurer la stabilité des infrastructures tout en s’adaptant aux évolutions d’affaires et technologiques quelquefois sous une forte pression des organisations clientes (signature d’un gros contrat par ex.).
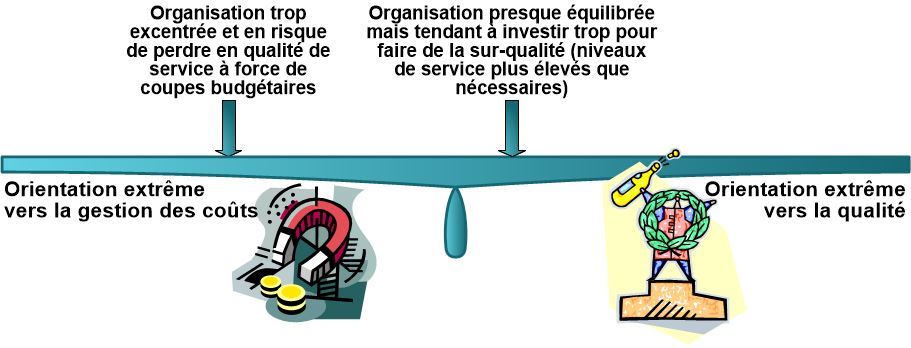
Conflit n°3 : Qualité de service contre coût de service
Il faut :
délivrer en continu les niveaux de service convenus aux utilisateurs et clients et
être au niveau optimal de gestion des coûts et des ressources
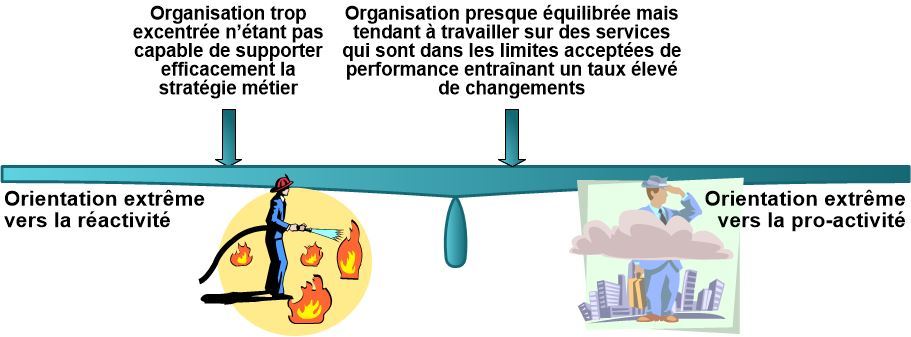
Conflit n°4 : Réactivité contre pro-activité
Les deux attitudes à concilier sont les suivantes :
organisation réactive : ne fait rien jusqu’à ce qu’un facteur externe l’oblige à réagir (on constate que les acteurs ne « s’éclatent » que lorsqu’il y a des incidents importants ou majeurs mais qu’ils ne font rien pour diminuer l’apparition de tels événements)
organisation pro-active : tout le temps en recherche d’amélioration de l’existant au-delà de ce qui est nécessaire d’un point de vue VOI (Value On Investment ou valeur sur investissement)
Périmètre couvert #

Réf. ITSM_M0500-V010-003
Implication des équipes opérationnelles dans la conception et la transition #

Réf. ITSM_M0500-V010-004
Apport de valeur pour le business #

Réf. ITSM_M0500-V010-005
Termes relatifs à l’exploitation des services #
Réf. ITSM_M0500-V010-006
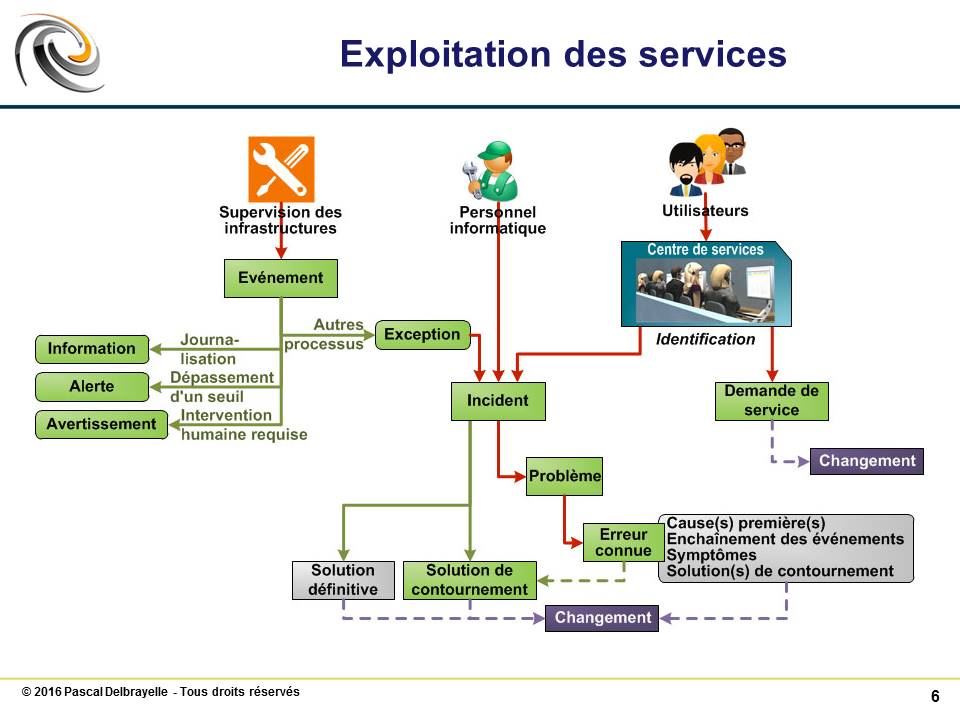
Evénement #
Changement d’état significatif pour la gestion d’un service informatique ou de tout autre élément de configuration.
Le terme « événement » est aussi employé pour désigner une alerte ou une notification créée par un service informatique, un élément de configuration ou un outil de surveillance. Les événements requièrent habituellement que le personnel des opérations informatiques initie une action ce qui conduit le plus souvent à la journalisation d’incidents.
Alerte #
Avertissement qu’un seuil a été atteint, que quelque chose a changé ou qu’une défaillance s’est produite.
Les alertes sont souvent créées et gérées par les outils de gestion des systèmes et sont gérés par le processus de gestion des événements.
Avertissement #
Nécessite une intervention humaine (le début du processus est très souvent automatisé et géré par des outils de supervision).
Incident #
Interruption non planifiée d’un service informatique ou réduction de la qualité d’un service informatique.
La défaillance d’un élément de configuration qui n’a pas encore eu d’impact sur le service est aussi un incident. Par exemple, la défaillance d’un seul des disques d’un ensemble de disques miroirs.
Solution de contournement #
Réduire ou éliminer l’impact d’un incident ou d’un problème pour lequel une résolution complète n’est pas encore disponible – par exemple, en redémarrant un élément de configuration défaillant.
Les solutions de contournement des problèmes sont documentées dans les enregistrements d’erreurs connues. Les solutions de contournement des incidents qui n’ont pas été associées aux enregistrements des problèmes sont documentées dans les enregistrements d’incidents.
Problème #
Cause d’un ou de plusieurs incidents.
Cette cause n’est pas forcément connue au moment de l’enregistrement d’un problème et le processus de gestion des problèmes est alors chargé des nouvelles investigations.
Erreur connue #
Problème pour lequel il existe une cause première et une solution de contournement documentées.
Les erreurs connues sont créées et gérées tout au long de leur cycle de vie par la gestion des problèmes. Les erreurs connues peuvent aussi être identifiées par le développement ou les fournisseurs.
Demande de service #
Demande formelle d’un utilisateur et qui n’est pas un incident.
Demande formelle d’un utilisateur pour quelque chose devant être fourni – par exemple, une demande d’information ou des conseils; pour réinitialiser un mot de passe, ou pour installer un poste de travail pour un nouvel utilisateur. Les demandes de service sont gérées par le processus d’exécution des requêtes, habituellement en conjonction avec le centre de services. Les demandes de service peuvent être liées à une demande de changement dans le cadre d’exécution de la demande.
Réf. ITSM_M0500-V010-007
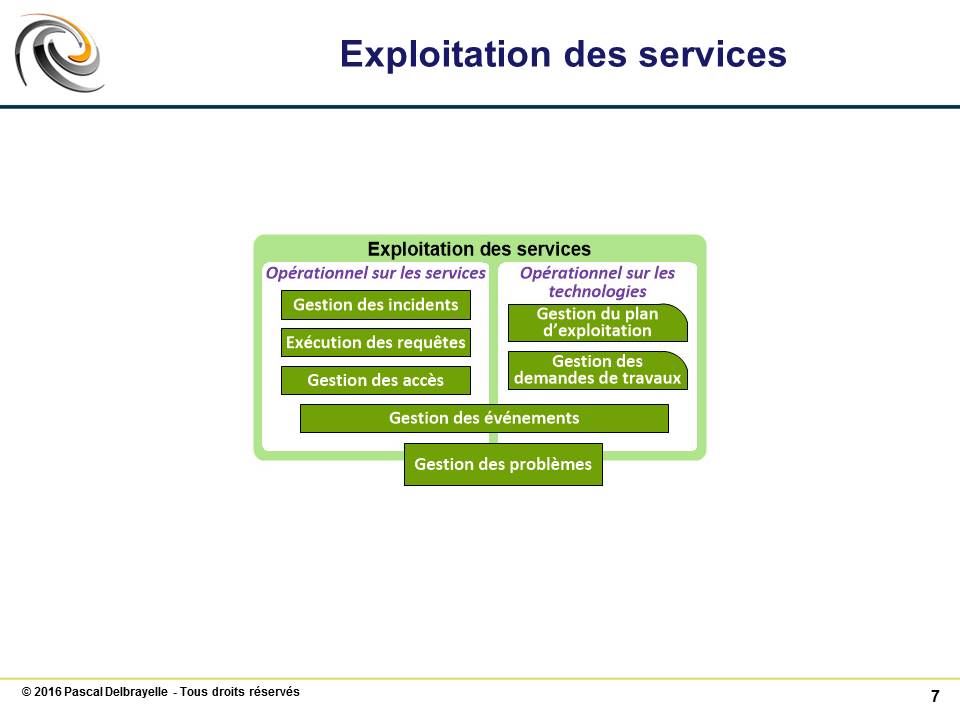
Processus #
Gestion des événements | Gérer les événements tout au long de leur cycle de vie (supervision) |
Gestion des incidents | Dépanner les utilisateurs le plus rapidement possible |
Exécution des requêtes | Traiter toutes les demandes de service |
Gestion des accès | Traiter toutes les demandes d’accès |
Gestion des problèmes | Traiter les problèmes et erreurs connues tout au long de leur cycle de vie |