
But et objectifs #

Réf. ITSM_M0520-V010-001

Réf. ITSM_M0520-V010-002
Exemples d’incident #
application : application non disponible, erreur programme empêchant l’utilisateur de travailler, nombre d’E/S disques excessif
matériel : système HS, remontée d’alerte automatique, sortie imprimante bloquée
Extensions de la définition d’un incident #
La version 2 de ITIL® définissait un incident comme « tout événement qui ne fait pas partie du fonctionnement standard d’un service et qui cause, ou peut causer, une interruption ou une diminution de la qualité de ce service. »
Le terme incident est généralement compris comme un dysfonctionnement signalé par un utilisateur. Cependant, deux extensions à cette définition sont généralement utilisées car elles vont suivre le même processus de traitement que les dysfonctionnements proprement dits et sont donc assimilés à des incidents :
les demandes pour un nouveau service (ou l’extension d’un service existant) sont considérées comme des demandes de service mais assimilées à des incidents en pratique (traitement identique dans l’outil de gestion des tickets) et traitées dans le cadre de la gestion des incidents (pour ITIL®, il s’agit d’une extension abusive car elles sont traitées par un processus à part)
les remontées d’alertes automatiques (espace-disque saturé par exemple) : elles sont souvent considérées comme faisant partie de l’exploitation courante ; ces événements sont parfois traités comme incidents dans le cadre de la gestion des incidents même si le service délivré aux utilisateurs n’est pas encore affecté
Réf. ITSM_M0520-V010-003
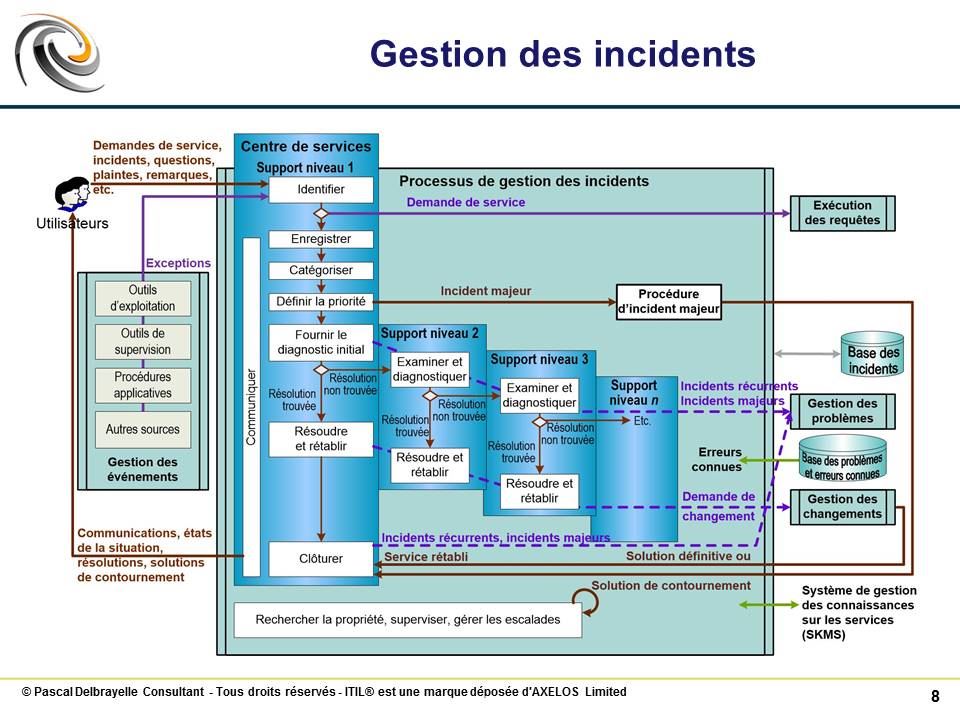
Entrées du processus #
En entrée du processus, nous retrouvons :
détails des incidents (du centre de services et des différentes sources automatiques)
détails des configurations (gérées par le CMS)
recherches de correspondances (matching) entre incidents et problèmes et erreurs connues
détails de résolution des incidents de nature similaire
retour des demandes de changement en correction d’un incident
Sorties du processus #
En sortie du processus, nous avons :
routage des demandes de service
demandes de changement et de demandes de changement standard pour résoudre certains incidents
mise à jour de la base des problèmes et des erreurs connues
communication aux utilisateurs (pendant l’avancement et à la fermeture)
rapports de performance du processus
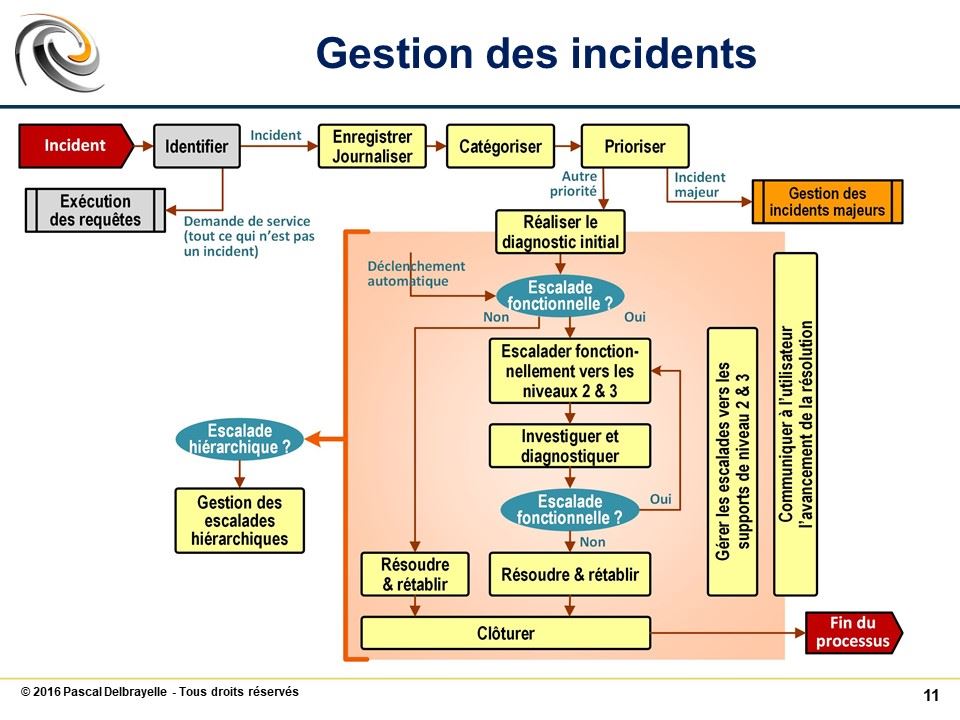
Séquence des activités du flux de traitement d’un incident #
Le traitement d’un incident passe par les étapes suivantes :
1. Identification
Il s’agit de séparer les incidents des demandes de service ; ces dernières seront redirigées vers le processus d’exécution des requêtes.
2. Enregistrement (ou journalisation)
Cette étape est simplement la création du ticket d’incident
3. Catégorisation
Cette étape consiste à remplir les données du ticket d’incident, en particulier les catégories pouvant être renseignées à ce stade.
4. Définition de la priorité
Le calcul de la priorité de l’incident est destinée à aiguiller le plus vite possible les incidents majeurs vers leur procédure de traitement spécifique et à prioriser le diagnostic et la résolution des différents incidents en cours.
5. Diagnostic initial
Cela consiste, pour le rôle de support de niveau 1 (joué par le centre de services) à trouver une solution évidente ou à trouver une solution dans l’ensemble des bases à disposition (documentation de support, incidents similaires déjà résolus, problèmes en cours, erreurs connues, etc.) ; dans le cas contraire ou après un certain délai, il faudra réaliser une escalade fonctionnelle vers un groupe de support de niveau 2
6. Investigation et diagnostic
Ces actions sont réalisées par les groupes de support 2 et supérieur (y compris des sous-traitants avec lesquels ont été passés des contrats de support); le principe est d’identifier le plus rapidement possible une solution pour résoudre l’incident et non pas d’essayer de comprendre tout ce qui s’est passé (voir processus de gestion des problèmes).
7. Résolution et rétablissement
Il s’agit d’appliquer la solution définitive ou la solution de contournement la plus rapide pour résoudre l’incident et dépanner l’utilisateur ; certaines résolutions se traduisent par une demande de changement ou une demande de changement standard.
8. Bilan et clôture
Réalisée par le support de niveau 1, cette activité peut intégrer les tâches suivantes :
confirmer la résolution avec l’utilisateur ou l’initiateur (celui qui a signalé l’incident)
préciser les catégories du ticket d’incident (en particulier la catégorie de la solution apportée) ou corriger celles qui sont déjà précisées
compléter l’enregistrement de l’incident
vérifier que les détails de la solution sont clairs et lisibles
vérifier que les codes de refacturation sont renseignés (cost-centre)
vérifier que les temps passés sur l’incident sont renseignés
envoyer un questionnaire de satisfaction à l’utilisateur
créer un problème car l’origine de l’incident n’est pas clairement établie ou n’est pas réglée (ce qui risque de voir revenir le même type d’incident)
Quelques remarques sur cette séquence d’activités #
le centre de services est responsable de l’aboutissement de tous les incidents enregistrés (il est le propriétaire de tous les incidents)
le processus de traitement est purement réactif
les incidents ne pouvant pas être résolus dans un délai raisonnable doivent être assignés aux groupes de spécialistes (niveaux de support supérieurs à 1, le centre de services
la résolution ou une solution de contournement doit intervenir le plus vite possible pour rétablir le service impacté
Préconisations sur la gestion du ticket d’incident #
Tout au long du cycle de vie de l’incident, l’enregistrement doit être à jour pour permettre à n’importe quelle personne de l’équipe du centre de services de communiquer sur l’incident simplement en consultant l’enregistrement.
Il est nécessaire de conserver la description originelle de l’incident même si la description en cours évolue. Par exemple, un utilisateur signale un incident avec son imprimante (son édition ne s’imprime pas). Après investigation, il s’agit en réalité d’un problème réseau mais, lorsque l’incident est clos, il est préférable que le centre de services prévienne l’utilisateur simplement en lui précisant que son souci d’imprimante est réglé plutôt que de lui expliquer le problème réseau et sa résolution.
Il faut aussi conserver un historique des modifications sur l’enregistrement de l’incident. Tous les changements d’état doivent être tracés (date/heure, personne qui a provoqué le changement, etc.). Ce point est aussi un point imposé par le processus de gestion des configurations (les tickets d’incidents sont aussi sous le contrôle de ce processus).
Si l’une des équipes n’a pas accès à l’outil de gestion des incidents, il est impératif de bien mettre en place une procédure de mise à jour de ces enregistrements à faire lors des interventions de ces équipes (par exemple: maintenance tierce ou support de nuit n’ayant pas accès à l’outil durant la nuit).

Réf. ITSM_M0520-V010-004

Réf. ITSM_M0520-V010-005
Les incidents majeurs #
Les incidents majeurs sont ceux pour lesquels le degré d’impact sur l’ensemble des utilisateurs et sur les affaires est extrême.
Devraient être considérés comme incidents majeurs les incidents pour lesquels l’échelle de temps des perturbations devient excessif au regard des temps de résolution (SLAs) (même si cela impacte un petit nombre d’utilisateurs).
Le gestionnaire des problèmes devrait être averti (s’il ne l’est pas déjà) afin d’organiser une réunion (ou une série de réunions) avec toutes les parties concernées :
équipes de support internes
équipes de support des matériels/logiciels (et/ou mainteneur)
équipes de gestion des environnements de production
Le centre de services devrait participer à ces réunions et enregistrer dans la base d’Incidents toutes les actions prises et les décisions.
Nous pouvons considérer qu’il s’agit là d’une période de crise qui ne peut pas être décrite de manière exhaustive dans une méthode car l’important est d’agir vite malgré le nombre peut-être important d’intervenants.
Cependant, on peut en déduire en pratique deux points à avoir en mémoire :
le traitement des incidents majeurs est sous la responsabilité du gestionnaire des problèmes
une information à jour et une communication cohérente sont importantes (évolution très rapide des informations et un besoin très fort en informations des équipes opérationnelles impliquées et des clients et utilisateurs impactés) ; ce rôle est rempli par le centre de services qui doit collecter ces informations et les enregistrer au niveau de ou des incidents déclarés.

Réf. ITSM_M0520-V010-006

Réf. ITSM_M0520-V010-007
Escalade fonctionnelle et escalade hiérarchique #
Escalade fonctionnelle
C’est l’escalade traditionnelle et prévue dans le processus pour transférer un incident d’un niveau au niveau supérieur.
Cette escalade peut intervenir dans deux cas :
par manque de connaissance ou d’expertise du niveau en cours
par dépassement d’un délai (à définir avec précaution et ne pas dépasser les délais des accords de niveaux de service)
Escalade hiérarchique
Ce type d’escalade n’est pas réellement prévue dans le processus. Cependant, en pratique, on constate que cette escalade existe et est nécessaire au bon fonctionnement du support dans certains cas.
L’escalade hiérarchique peut intervenir à n’importe quel moment dans le cycle de gestion de l’incident lorsqu’il est évident que la résolution interviendra hors-délai ou sera insatisfaisante. Ceci demande un certain recul vis-à-vis du processus qui, s’il est suivi à la lettre, peut aboutir dans certains cas à des situations critiques.
Dans l’idéal , l’escalade hiérarchique devrait intervenir avant la fin du délai pour que la hiérarchie ait le temps de réagir. En pratique, on constate que l’escalade hiérarchique est utilisée lorsque les temps de résolution de l’Incident sont hors délai.
Exemple de processus #
Réf. ITSM_M0520-V010-008
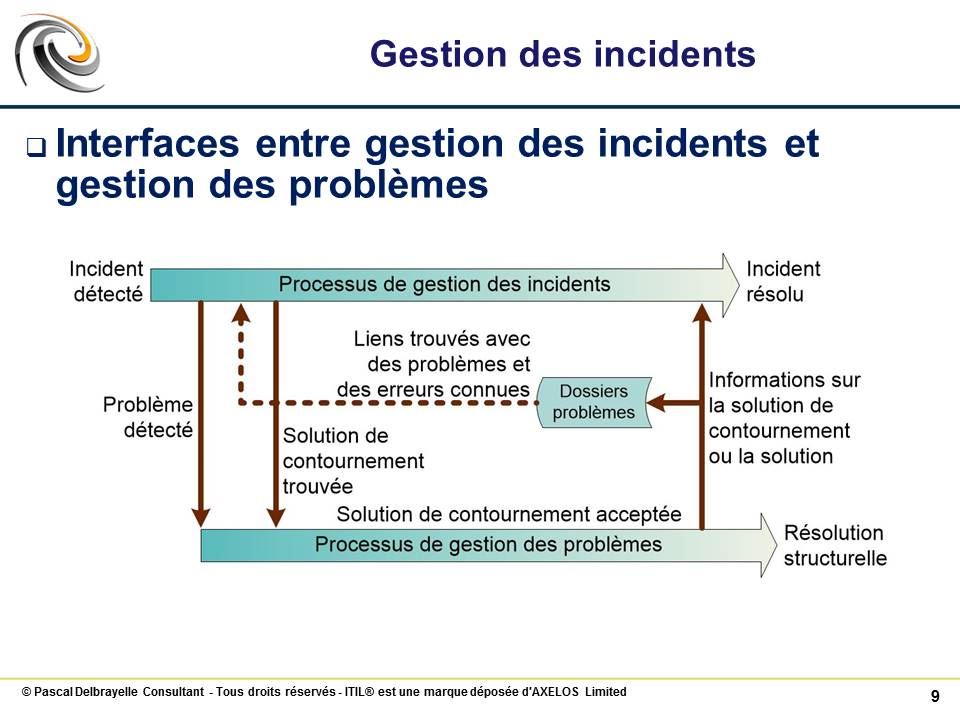
Interfaces entre gestion des incidents et gestion des problèmes #
Réf. ITSM_M0520-V010-009
Les interactions entre les processus de gestion des incidents et de gestion des problèmes sont complexes mais il est nécessaire de les maîtriser afin de bien séparer ces deux processus dont les finalités sont très différentes.
Dans le traitement d’un incident, les actions suivantes doivent être entreprises :
si l’incident semble avoir une cause inconnue, initier un problème pour déclencher le processus de gestion des problèmes
étudier une correspondance avec les problèmes référencés et les erreurs connues
étudier une correspondance avec les incidents référencés (similaires résolus ou en cours)
si aucune solution n’a été identifiée, la gestion des incidents a la responsabilité d’en trouver une (définitive ou de contournement) avec l’impact minimum sur l’activité de l’entreprise
Les flux entre la gestion des incidents et la gestion des problèmes sont croisés :
lors de l’analyse de l’incident par la gestion des incidents pour restaurer le plus vite possible le service impacté, si une solution de contournement a été trouvée, l’information doit être transmise à la gestion des problèmes pour analyse
lors de l’analyse du problème par la gestion des problèmes, une solution définitive ou de contournement à un ou plusieurs incidents est trouvée, la gestion des problèmes met alors à jour la base des problèmes/erreurs connues et met l’information à disposition de la gestion des incidents pour action sur les incidents liés (passage des incidents en résolu par l’application de la solution de contournement)
Apport de valeur pour l’entreprise #

Réf. ITSM_M0520-V010-010

Réf. ITSM_M0520-V010-011
Défis classiques #

Réf. ITSM_M0520-V010-012
Voici quelques préconisations utiles et quelques difficultés à prévoir lors de la mise en oeuvre du processus et sa planification.
Séquencement et calendrier
ne pas mettre en place de manière isolée des autres processus et fonctions (centre de services, gestion des problèmes, gestion des actifs de service et des configurations, gestion des changements, gestion des mises en production et des déploiements)
si cela n’est pas possible, il est nécessaire d’implanter au moins en même temps centre de services et gestion des incidents (objectifs rapides ou quick wins à atteindre)
profiter des démarrages de services importants pour les intégrer tout de suite dans une gestion des incidents (même si le nombre d’utilisateurs ou le nombre d’appels ne justifient pas dans ce cas la mise en place d’un centre de services et d’une gestion des incidents)
planification de la mise en place du processus : 3 à 6 mois
mise en place du processus et consolidation : 3 mois à 1 an
choix des outils logiciels : prendre les logiciels conformes à ITIL®
CMS inexistant ou pas mis en place en même temps : intégrer les informations de configuration dans la base de gestion des incidents
Difficultés à prévoir
pas d’engagement de la hiérarchie
manque de clarté des besoins d’affaires
méthodes de travail non revues
pas d’informations sur les niveaux de service
manque de connaissances des incidents résolus
manque d’intégration avec les autres processus
résistance au changement