
Objectifs #

Réf. ITSM_M0530-V010-001
Modes réactif et pro-actif #

Réf. ITSM_M0530-V010-002
Concepts de base #
Les incidents récurrents
Pour traiter correctement et rapidement un incident récurrent qui se présente, il est indispensable que les informations (conseils, solution) soient disponibles et accessibles rapidement (pertinence, facilité d’interprétation) ceci dès les premières phases d’un incident.
Très peu d’incidents arrivant au centre de services sont nouveaux et inédits. Les équipes de support ont déjà rencontré et résolu des incidents similaires par le passé.
L’utilisation optimale de ces informations est de les documenter de telle manière que le support de premier niveau puisse les utiliser facilement.
Plus que de l’écriture de documentations
L’information doit être indexée de manière pertinente et des examens réguliers de la pérennité des informations au regard des changements de l’infrastructure doivent être menées régulièrement.
Il faut aussi former les équipes qui vont utiliser l’information (accès, interprétation) et avoir un retour des équipes sur l’utilisation de l’outil. Il faut en effet utiliser un outil logiciel intégré (transversal sur la gestion des services).
Le référentiel ITIL® suggère aussi l’utilisation de systèmes experts.
« Matières premières » des problèmes et erreurs connues
analyse des incidents en cours (mode réactif)
analyses statistiques des incidents (mode proactif ou préventif)
analyses de l’infrastructure informatique
consultation de bases de problèmes (externes)
documentations des services (d’affaires ou techniques) mis en production
La gestion des incidents contre la gestion des problèmes ?
La gestion des problèmes recherche la cause d’un ou de plusieurs incidents et y remédie.
Souvent, cet objectif est en conflit avec l’objectif principal de la gestion des incidents (redémarrer le service au plus vite). En effet, il arrive que la mise en place d’une solution de contournement soit antagoniste avec la recherche de la cause.
Prenons l’exemple d’un crash système :
la gestion des incidents demandera de redémarrer le système immédiatement afin de minimiser le temps d’indisponibilité du serveur
la gestion des problèmes demandera à différer le redémarrage du système car ce redémarrage peut supprimer des fichiers journaux contenant des informations sur l’origine du crash entraînant une perte d’informations pour trouver la cause du crash (et beaucoup de crash systèmes demeurent mystérieux…)
Activités du processus
Réf. ITSM_M0530-V010-003
Entrées du processus #
détails des incidents de la gestion des incidents
détails des configurations des bases de données de la gestion des configurations
toute solution de contournement mise en place par la gestion des incidents
Sorties du processus #
génération des erreurs connues
émission de demandes de changement (RFCs ou Requests For Change)
mise à jour des enregistrements de problèmes (incluant une solution définitive et/ou de contournement)
fermeture des enregistrements de problème
réponse sur la correspondance entre incidents et problèmes/erreurs connues
informations de synthèse
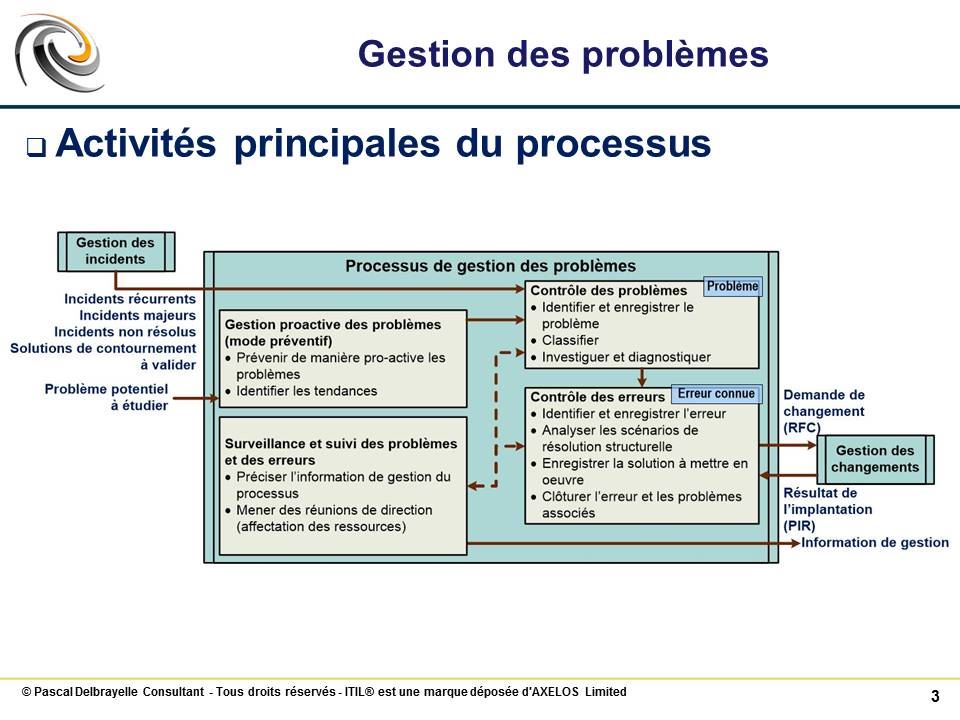
Activités principales de la Gestion des Problèmes #
Contrôle des problèmes #
L’objectif du contrôle des problèmes est d’identifier la cause première (élément de configuration défaillant par ex.) et de fournir au centre de services des informations sur les solutions de contournement quand elles existent.
Qui définit les solutions de contournement ?
la gestion des incidents en définit dans l’urgence (une ou plusieurs)
la gestion des problèmes étudie ces solutions de contournement (et d’autres) et valide la meilleure
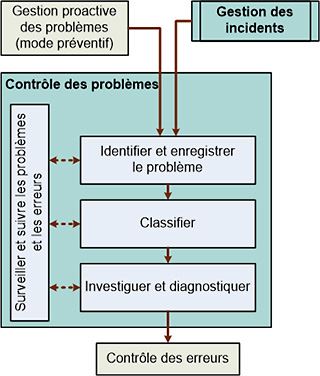
1. Identification et enregistrement du problème
Les différentes sources sont :
enregistrement de nouveaux incidents
analyse des incidents
analyse de l’infrastructure informatique (problèmes pouvant potentiellement générer des incidents)
incident majeur ou significatif nécessitant une solution structurelle
D’autres sources en dehors de l’exploitation des services existent, parmi lesquelles :
la gestion de la capacité
la gestion de la disponibilité
Il est à noter que :
l’organisation peut décider de ne pas lancer d’analyse sur certains problèmes (coût non justifié et classement sans suite)
l’enregistrement du problème est similaire à celui d’un incident (différence principale : pas de reprise des données utilisateurs dans l’enregistrement du problème)
2. Classification du problème
Elle est similaire à la classification d’un incident :
catégorie : groupes de domaines techniques (calqués sur l’organisation des fonctions gestion technique et gestion des applications)
impact : effet sur les activités d’affaires (utiliser les liens dans la CMDB et codification en relation avec les organisations clientes)
urgence : délai maximum que peut supporter la résolution d’un problème
priorité : ordre de traitement d’un élément dans une liste d’attente
Quelques rappels :
Priorité : il s’agit principalement d’une combinaison impact & urgence mais aussi de risques de défaillance et de disponibilité des ressources ; la priorité est à modifier en utilisant le bon sens et en ayant à l’esprit les activités d’affaires (ne pas appliquer systématiquement à la lettre ce que donne la combinaison impact & urgence)
Impact : l’une des difficultés est qu’il s’agit d’une classification à un instant donné (elle peut évoluer dans le temps). Par exemple, l’un des facteurs est l’évolution du nombre d’incidents associés au problème en cours de résolution (ce nombre peut devenir préoccupant au fil du temps et peut nécessiter d’augmenter la priorité pour que le problème soit résolu plus rapidement). C’est pour cela qu’il est intéressant de définir un compteur d’incidents associés à un problème et de définir des seuils de dépassement de ce compteur afin d’alerter automatiquement en cas de dépassement de ce seuil
3. Investigation et diagnostic sur le problème
La création d’une erreur connue nécessite d’identifier le ou les éléments de configuration à l’origine des incidents. Si aucun élément de configuration est directement en cause, il peut être intéressant de créer un élément de configuration factice pour travailler ensuite sur l’erreur connue.
Voici un exemple : beaucoup d’incidents sont liés à un manque général et connu de formation des utilisateurs. Il est possible alors de créer un élément de configuration « problème de formation » et associer le problème et l’erreur connue sur cet élément factice.
Attention : les spécialistes travaillent souvent sur la résolution des incidents (prioritaire) et la résolution des problèmes et il est nécessaire de bien équilibrer le temps passé sur ces deux processus.
Contrôle des erreurs #
L’objectif est d’éradiquer les erreurs connues en émettant vers la gestion des changements des demandes de changement (RFCs) et en les suivant jusqu’à leur mise en place effective.
Il faut donc être au courant des erreurs existantes, il faut les surveiller et les éradiquer quand cela est possible et justifiable budgétairement.
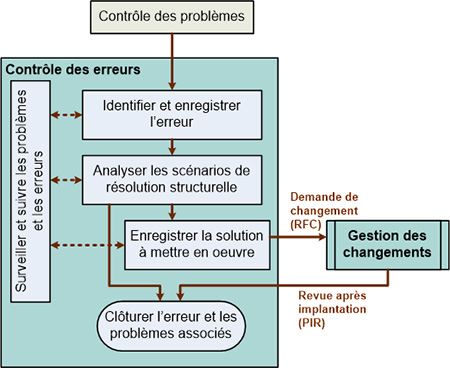
1. Identification et enregistrement de l’erreur
Une erreur est identifiée lorsque l’élément de configuration (CI) en faute est identifié.
Le statut d’erreur connue est assigné lorsque :
la cause première du problème est trouvée ET
une solution de contournement a été trouvée
Deux sources d’erreurs connues existent :
celle de l’environnement de production
celle des environnements de développement et de test (livraison d’application avec des erreurs connues)
2. Evaluation de l’erreur et enregistrement de la résolution de l’erreur
L’équipe de gestion des problèmes fait une évaluation initiale de l’erreur. Si nécessaire, elle initialise une demande de changement (RFC) transmise à la gestion des changements.
Les étapes finales de la résolution (analyse d’impact, évaluation complète, modification de l’élément de configuration, test de validation) sont sous le contrôle de la gestion des changements.
L’enregistrement détaillé de la résolution est essentiel pour la gestion des incidents lors de l’apparition d’incidents récurrents.
3. Contrôle des erreurs pour les environnements applicatifs
Le processus est sensiblement le même dans l’environnement de production et dans l’environnement de développement :
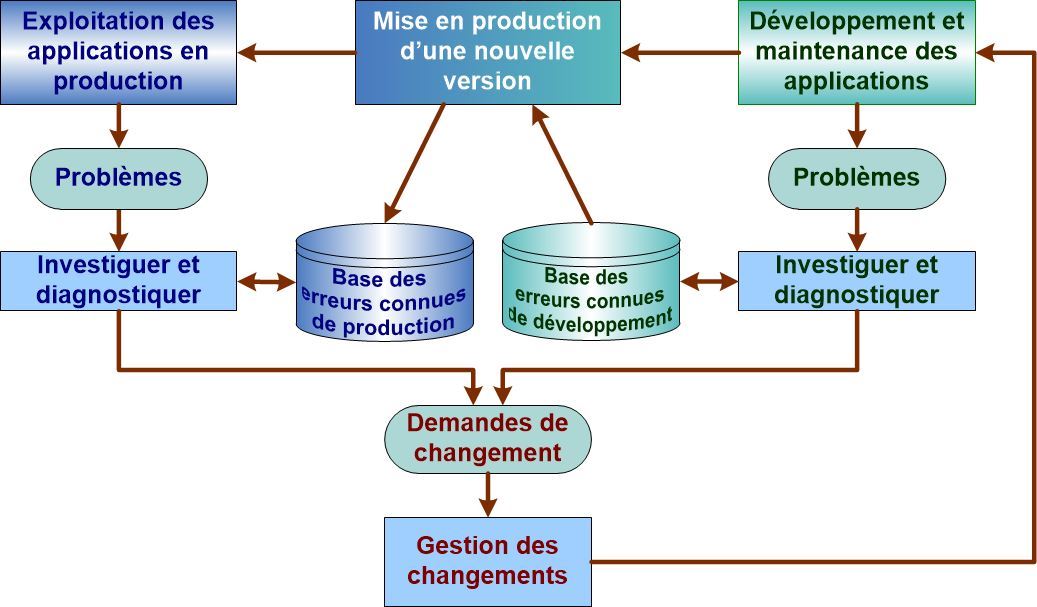
Il y a des échanges cycliques entre la gestion des problèmes des deux environnements.
4. Fermeture de l’erreur et des problèmes associés
Après la mise en place du changement correctif :
préconisation : à la fermeture de l’erreur et des problèmes, utiliser un statut provisoire « Closed pending PIR » ou « Fermé, en attente de validation » (PIR=Post Implementation Review)
5. Surveillance et suivi des erreurs
La mise en place des changements s’effectue sous la responsabilité de la gestion des changements et est suivie par la gestion des problèmes.
En attendant la mise en place effective du changement, il faut surveiller les incidents et problèmes relatifs à l’erreur connue et déclencher une alerte si dépassement d’un seuil (nombre) défini dans le cadre des accords de niveaux de service (SLAs). Cela permet de décider d’augmenter la priorité d’une demande de changement par exemple.
6. Quelques remarques générales
Toutes les erreurs connues n’ont pas besoin d’être corrigées pour une raison ou une autre :
résolution trop chère en regard des résultats attendus
résolution techniquement impossible
trop de temps pour résoudre
Globalement, une demande de changement concerne des aspects techniques mais peut aussi adresser des modifications
de procédures
de méthodes de travail
d’organisation
Gestion pro-active des problèmes #
L’objectif est d’identifier et de résoudre les problèmes avant que des incidents ne surviennent en conséquence de ces problèmes, entraînant des perturbations pour les utilisateurs.

1. Analyse des tendances
L’objectif est d’identifier les éléments de configuration qui fragilisent l’infrastructure (impact, risque de panne).
Les sources d’informations sont, entre autres, les suivantes :
base d’incidents, de problèmes et d’erreurs connues
outil de supervision de l’infrastructure et données collectées par le processus de gestion des événements
informations externes (veille technologique)
utilisateurs (enquêtes de satisfaction, groupes de travail, etc.)
Deux types d’actions vont être envisagées selon la catégorie :
identification d’erreurs (isolées) dans l’infrastructure (transmis au contrôle des problèmes et des erreurs pour correction)
identification de problèmes plus généraux nécessitant des actions de fond (et traitées dans l’activité proactive d’initialisation d’actions préventives)
2. Initialisation d’actions préventives
L’objectif est d’initialiser des actions préventives générales dans les domaines posant le plus de problèmes.
Il peut être utile pour analyser des statistiques de définir un facteur de pénibilité (pain factor) comme, par exemple :
volumétrie d’incidents
nombre d’utilisateurs impactés
la durée et le coût de résolution des incidents
le coût pour les activités d’affaires (en fait, le plus important)
Ceci permet une approche globale sur l’ensemble des incidents et problèmes sans se focaliser a priori sur une catégorie particulière d’incidents ou de problèmes.
Une fois identifié, une action préventive sera initialisée. Par exemple :
donner un retour sur les tests, procédures, formation, documentations
lancer des actions de formation (utilisateurs, équipes supports)
Traitement d’un problème et d’une erreur connue #
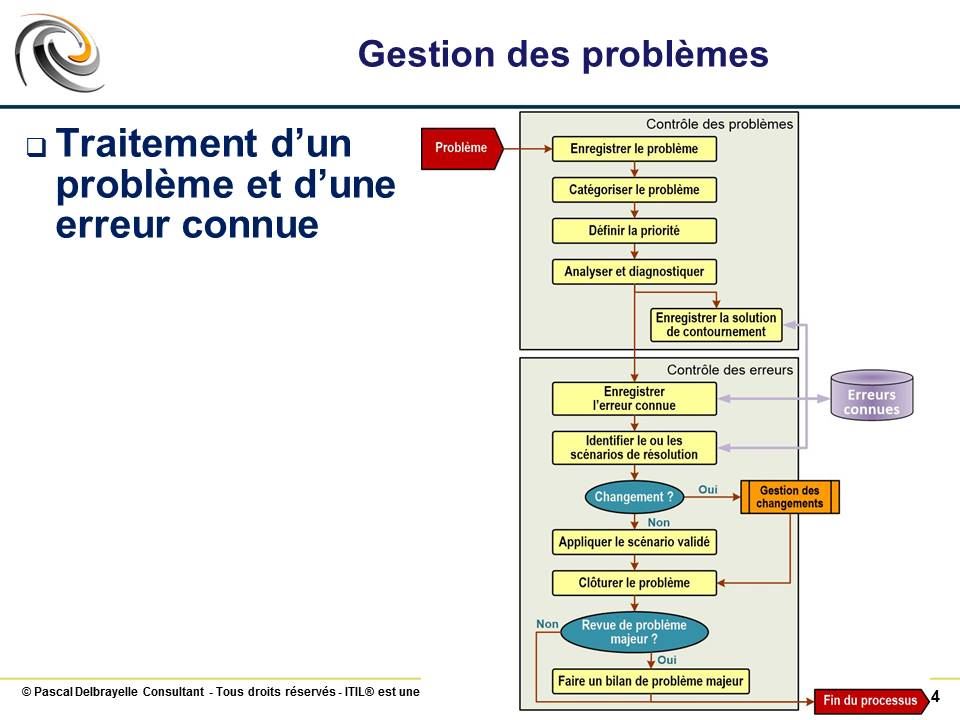
Réf. ITSM_M0530-V010-004
En plus du détail précédent, un traitement particulier est accordé à un problème majeur en fin de processus.
Un problème majeur est initié à la suite de chaque incident majeur pour
expliquer l’enchaînement des événements ayant abouti à l’incident majeur
identifier un plan d’actions pour améliorer l’environnement de production pour éviter qu’un incident majeur identique ne se reproduise
valider et exécuter le plan d’actions
Revue des problèmes majeurs #
L’objectif est de réaliser une réunion et de rédiger un compte-rendu avec les acteurs impliqués dans la résolution de l’incident majeur pour déterminer :
ce qui a été fait correctement
ce qui a été fait de manière incorrecte
ce qui pourrait être mieux fait la prochaine fois
comment anticiper le problème pour qu’il ne réapparaisse plus
Niveaux de maturité du processus #
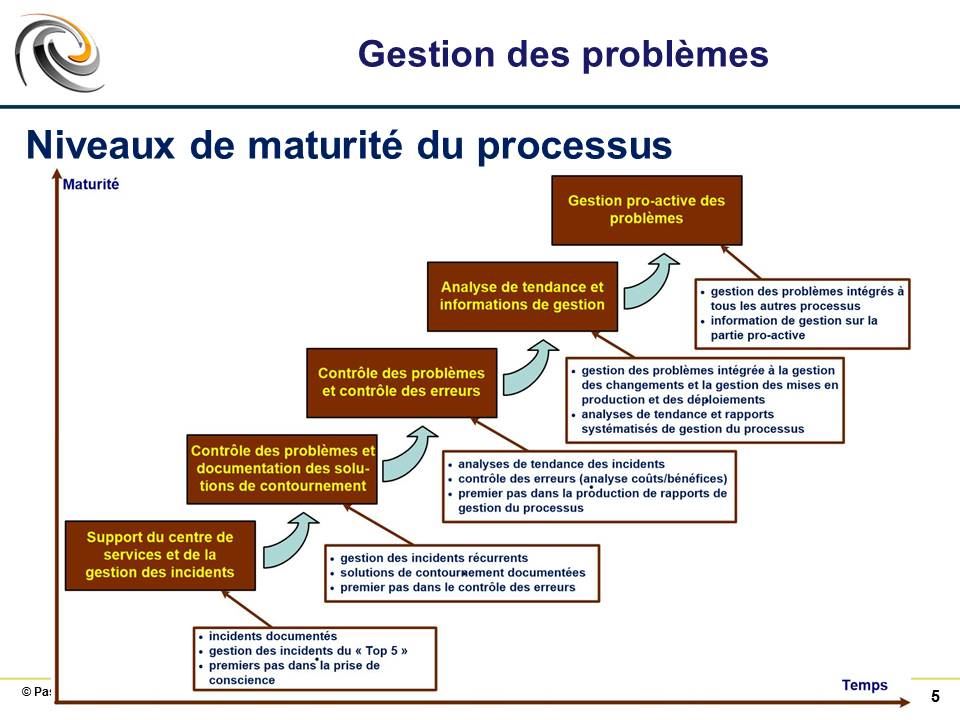
Réf. ITSM_M0530-V010-005
Apport de valeur pour le business #

Réf. ITSM_M0530-V010-006

Réf. ITSM_M0530-V010-007